La seguridad es lo primero: algoritmos de verificación y detección de posición del encóder óptico absoluto RESOLUTE™
Este artículo técnico incluye una descripción general del funcionamiento del encóder absoluto RESOLUTE y describe detalladamente los aspectos de seguridad de sus algoritmos de verificación y detección de posición.
Introducción
La serie RESOLUTE de encóderes absolutos funciona de manera totalmente distinta a los encóderes absolutos tradicionales, ya que generan un indicador de error que se establece si el resultado de la posición es incorrecto. Esto aumenta los niveles de seguridad del operario de los sistemas de movimiento y simplifica el proceso de diseño del fabricante del sistema.
RESOLUTE calcula la posición a petición, mientras que los encóderes absolutos tradicionales funcionan sobre una base continua. Cuando está en uso, la cabeza lectora recibe una serie de señales de petición del sistema de control anfitrión. Cada vez que recibe una petición, la cabeza lectora determina la posición mediante dos métodos independientes (descritos a continuación), los cuales trabajan mediante principios de funcionamiento diferentes evitando el riesgo de que se genere un error general. Las posiciones resultantes se comparan para decidir si se debe establecer un indicador de error adjunta a la posición enviada al sistema de control. Es decir, el sistema de control puede confiar que un indicador de error se ha enviado desde la cabeza lectora. Si no se establece un indicador de error, el resultado de posición es siempre correcto.
Método de cálculo de la posición
RESOLUTE es un encóder óptico que utiliza una regla de medición formada por líneas oscuras sobre un sustrato brillante, como muestra la Figura 1. El periodo principal de la regla es 30 µm, pero algunas líneas concretas son omitidas para codificar la información de posición.

Figura 1: Imagen de regla absoluta
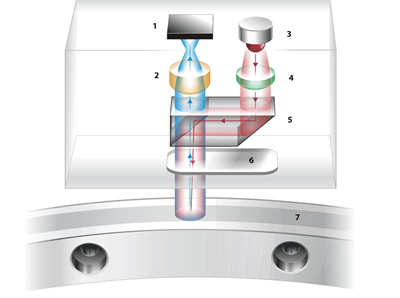
Figura 2: Esquema óptico de RESOLUTE
1. Sensor de imagen 2. Lente del detector 3. LED 4. Lente del colimador
5. Prisma divisor del haz 6. Ventana de la cabeza lectora 7. Regla absoluta
Cuando el encóder recibe una solicitud de posición, captura una imagen instantánea y precisa del área de la regla. Un diodo emisor de luz (LED) y un obturador electrónico en el sensor de imágenes, como muestra la Figura 2, se accionan durante 100 ns aproximadamente. El resultado es una imagen cronometrada a ±20 ns sin desenfoque por movimiento. A continuación, la imagen se transfiere al procesador de señales digital (DSP), instalado en la cabeza lectora, y se calcula la posición mediante dos algoritmos individuales:
Algoritmo 1 calcula la posición descodificando una imagen individual sin utilizar información de posiciones anteriores. La primera fase del proceso consiste en calcular la fase de la imagen; esta es similar a la ejecutada por encóderes incrementales y genera una respuesta correspondiente a una fracción del periodo básico de la regla, es decir, un valor entre 0 y 30 µm, con una resolución superior a 1 nm. Cada imagen de la regla alcanza aproximadamente 2 mm en la dirección de medición, ya que la regla está diseñada de forma que todas las imágenes dispongan de las líneas oscuras suficientes para calcular la fase con precisión. Este cálculo de fase define el rendimiento de la precisión a corta distancia, resolución y “ruido” del encóder.
La información de fase se utiliza para localizar el centro de cada línea potencial de la regla. Seguidamente, se establece la correlación de la imagen en cada una de estas posiciones para verificar si existe o no una línea oscura. Se genera un número binario de 65 bits que corresponde al patrón de la escala directamente debajo de la cabeza lectora. Solo se necesita una cuarta parte de estos bits para definir una posición única. Los bits restantes proporcionan información redundante, por lo que es posible determinar la posición correcta incluso si parte de la regla está oscurecida. A continuación, se utiliza un algoritmo de detección y corrección de errores para convertir la secuencia de bits a la posición absoluta de la cabeza lectora. La posición 1 completa del algoritmo se forma mediante la combinación de la posición aproximada (número total de ciclos de la regla) y la información de fase.
Algoritmo 2 calcula la posición extrapolando las dos lecturas de posición más recientes. Para el cálculo, se presupone que la velocidad del encóder desde la lectura anterior es la misma que la velocidad medida entre las dos posiciones anteriores. El error de este cálculo se determina por el tiempo transcurrido entre lecturas secuenciales, la precisión de las lecturas anteriores, las posibles incertidumbres de sincronización y la aceleración relativa de la cabeza lectora y la regla. Para un sistema típico que solicita la posición cada 62,5 µs, con una aceleración máxima entre la cabeza lectora y la regla de 100 m/s2 (10 g), el algoritmo 2 presenta un error máximo de ±1,2 µm. La cabeza lectora se asegura de que nunca transcurran más de 75 µs entre imágenes, por lo que captura imágenes adicionales entre peticiones cuando es necesario.
Comparación de posición
Una vez calculadas las dos posiciones, el encóder decide qué dato de posición debe enviar y si debe establecer o no un indicador de error. La parte de la fase del cálculo del algoritmo 1 es muy sólida. Si la regla se contamina, la información de fase recibe más interferencias y puede distorsionarse. No obstante, incluso en circunstancias extremas, el error de posición que se genera es de menos de un micrómetro. La información de fase sigue siendo fiable con un nivel de contaminación considerable, pero la capacidad de corrección de errores del cálculo de posición aproximada puede ser insuficiente para descodificar correctamente la posición absoluta.
La posición calculada por el algoritmo 2 facilita una posición aproximada sólida, ya que solo una aceleración extrema (>2 000 m/s2) puede provocar un error lo suficientemente grave para alterar la posición aproximada. No obstante, la posición precisa (fase) del algoritmo 2 no es muy exacta, ya que presupone que la velocidad es constante.
Durante el funcionamiento, si las posiciones aproximadas calculadas por los dos algoritmos coinciden, lo que equivale a que las posiciones totales empiecen a ±15 µm (la mitad de un periodo de la regla) entre ellas, la cabeza lectora genera esta posición aproximada junto a la fase del algoritmo 1. Simultáneamente, se pone a cero un contador interno; la importancia de este contador se hará evidente en su momento. Si las posiciones aproximadas no coinciden, la cabeza lectora genera la fase desde el algoritmo 1 junto con la posición aproximada del algoritmo 2 e incrementa el contador interno. Si el valor del contador interno supera el valor de cuatro en algún momento, la cabeza lectora establece un indicador de error, ya que no se puede asegurar que el resultado de posición sea correcto. En este punto, se recomienda examinar algunos ejemplos sobre los motivos para establecer un indicador de error:
Ejemplo 1
Se presupone que la cabeza lectora pasa sobre un área de contaminación que sobrepasa la capacidad de corrección de errores del código de la regla. El resultado es una posición aproximada incorrecta desde el algoritmo 1. No obstante, se generará la fase correcta, a pesar de una imprecisión de menos de un micrómetro provocada por la contaminación. La cabeza lectora registra internamente la discrepancia entre las posiciones aproximadas (incrementando su contador) y genera la posición aproximada correcta desde el algoritmo 2 con la fase correcta del algoritmo 1. Si la cabeza lectora no puede verificar la posición aproximada correcta del algoritmo 1 en cinco imágenes consecutivas, establece un indicador de error para indicar que la posición ya no es segura. Si el algoritmo 1 verifica la posición aproximada correcta en cuatro imágenes o menos, pone a cero el contador y continúa con la generación de posición.
Ejemplo 2
Se presupone que la cabeza lectora funciona normalmente y se ejecuta una aceleración de ~10 000 m/s2, equivalente a una deceleración de 2 m/s hacia una posición estacionaria en 100 µm, que podría deberse al movimiento de la máquina hacia un punto de parada fijo. En este caso, la posición del algoritmo 1 siempre es correcta, mientras que el algoritmo 2 retrasa la posición correcta en apenas unos periodos de la regla. La cabeza lectora asume (equivocadamente) que la posición aproximada del algoritmo 2 es correcta, y genera este resultado junto con la fase correcta del algoritmo 1. A partir de aquí, las posiciones aproximadas de los dos algoritmos serán siempre distintas. Seguidamente, la cabeza lectora calcula cinco posiciones que retrasan ligeramente la posición real antes de establecer un indicador de error.
Ejemplo 3
En este ejemplo, se presupone que los dos algoritmos fallan al mismo tiempo. Analicemos el caso poco probable de que la radiación ionizante dañe una zona de la memoria del procesador de la cabeza lectora, de forma que se corrompan las posiciones de los dos algoritmos. Puesto que los algoritmos calculan la posición de manera tan distinta, es impensable que puedan dañarse de forma que ambos generen la misma respuesta incorrecta. Entonces, la cabeza lectora detecta que las posiciones aproximadas no coinciden, por lo que incrementa su contador y genera la posición incorrecta compuesta por la parte aproximada del algoritmo 2 y la fase del algoritmo 1. Puesto que el algoritmo 2 se basa en lecturas anteriores, a partir de este punto la respuesta será siempre incorrecta. Por lo tanto, aunque el algoritmo 1 se recupere y genere la respuesta correcta, la cabeza lectora seguirá estableciendo un inducador de error tras calcular cinco posiciones incorrectas.
Respuesta del indicador de error
En los ejemplos anteriores, se indica que la cabeza lectora puede generar hasta cinco posiciones incorrectas antes de establecer el indicador de error. En un sistema típico que solicita la posición cada 62,5 µs, transcurren 313 µs desde que se genera la primera posición incorrecta hasta que se establece el error. En un sistema más lento, que solicita la posición a intervalos de 500 µs, este tiempo es de 500 µs, ya que la cabeza lectora tiene que procesar seis imágenes más cada dos solicitudes, para asegurar que el tiempo entre imágenes no supere los 75 µs. En ambos casos, el tiempo transcurrido desde que se genera la posición incorrecta hasta que se establece el indicador de error es lo suficientemente corto como para tomar las medidas adecuadas de respuesta al banderín de error, antes de que los datos incorrectos puedan afectar al sistema de control.
Las Figuras 3 y 4 muestran ejemplos de contaminación de la regla que permiten determinar la fase, pero anulan la extracción de código absoluta. En estos casos, los mecanismos descritos mantienen la posición correctamente o advierten de lo contrario mediante un banderín de error.

Figura 3: La contaminación de partículas oscurece amplias áreas de la regla, no obstante, es posible determinar la información de fase.

Figura 4: La contaminación por grasa provoca dispersión compleja de la luz, no obstante, apenas afecta a la información de fase.
Alimentación del sistema
En este punto, se presupone que el algoritmo 2 dispone siempre de los datos históricos suficientes para extrapolar la posición. Esto no ocurre inmediatamente después de conectar la cabeza lectora a la alimentación eléctrica, ya que no existe ninguna posición extrapolada para comparar la lectura de la regla. En este caso, se aplican dos métodos para aumentar la confianza en la posición de la cabeza lectora relativa a la regla.
En primer lugar, la cabeza lectora establece automáticamente el indicador de error si el contraste de la imagen no es aceptable. Después, se aplica una restricción sobre el alcance de corrección de errores disponible. Puesto que el código de la regla utiliza datos redundantes para garantizar un gran número de bits que distinguen entre secuencias válidas, esta restricción sobre los bits que se pueden corregir reduce considerablemente el riesgo de que una secuencia de bits pueda descodificarse incorrectamente como una posición falsa. Estas dos restricciones hacen que la inmunidad a la contaminación de la cabeza lectora se reduzca ligeramente durante el arranque. Para contrarrestarlo, la cabeza lectora obtiene gran cantidad de imágenes durante el proceso de inicio para que las interferencias no limiten su capacidad para verificar la posición.
Además, en el caso muy poco probable de que la cabeza lectora no detecte una posición incorrecta durante el arranque, el diseño del código de la regla permite detectar la discrepancia con un movimiento de 500 µm. En este caso, se establece el indicador de error.
CRC
Cuando la cabeza lectora termina de calcular las señales de error, se ejecuta una comprobación de redundancia cíclica (CRC), que se adjunta a los datos antes de transmitirlos al control del servidor. La transmisión se realiza mediante señales diferenciales a través de un cable con doble apantallado. A la recepción de los datos, se vuelve a calcular la CRC y se compara con el valor transmitido. Una diferencia en estos valores indica que los datos se han dañado durante la transmisión. De este modo, se detectan de forma precisa las posibles alteraciones de posición o las señales de error. Una ventaja adicional del uso de protocolos serie en vez de los sistemas de cuadratura tradicionales es que cada transmisión es independiente, por tanto, no se acumulan errores de transmisión. Esto, combinado con el funcionamiento exclusivo de RESOLUTE, proporciona al operario una ventaja de seguridad crucial, ya que no pueden producirse errores de recuento, desviación de posición o ‘pérdidas’ de recuento.
